
This is the sixth and LAST in a series of blog posts for folks who are into the geeky mathematical details of how Election Graphs state polling averages have compared to the actual election results from 2008, 2012, and 2016. If this isn’t you, feel free to skip this series. Or feel free to skim forward and just look at the graphs if you don’t want or need my explanations.
If you just want 2020 analysis, stay tuned, that will be coming soon.
You can find the earlier posts here:
- Polling Averages vs Reality
- Win Chances from Poll Averages
- Polling Error vs Final Margin
- Predicting 2016 by Cheating
- Criticism and Tipping Points
The electoral College trend chart
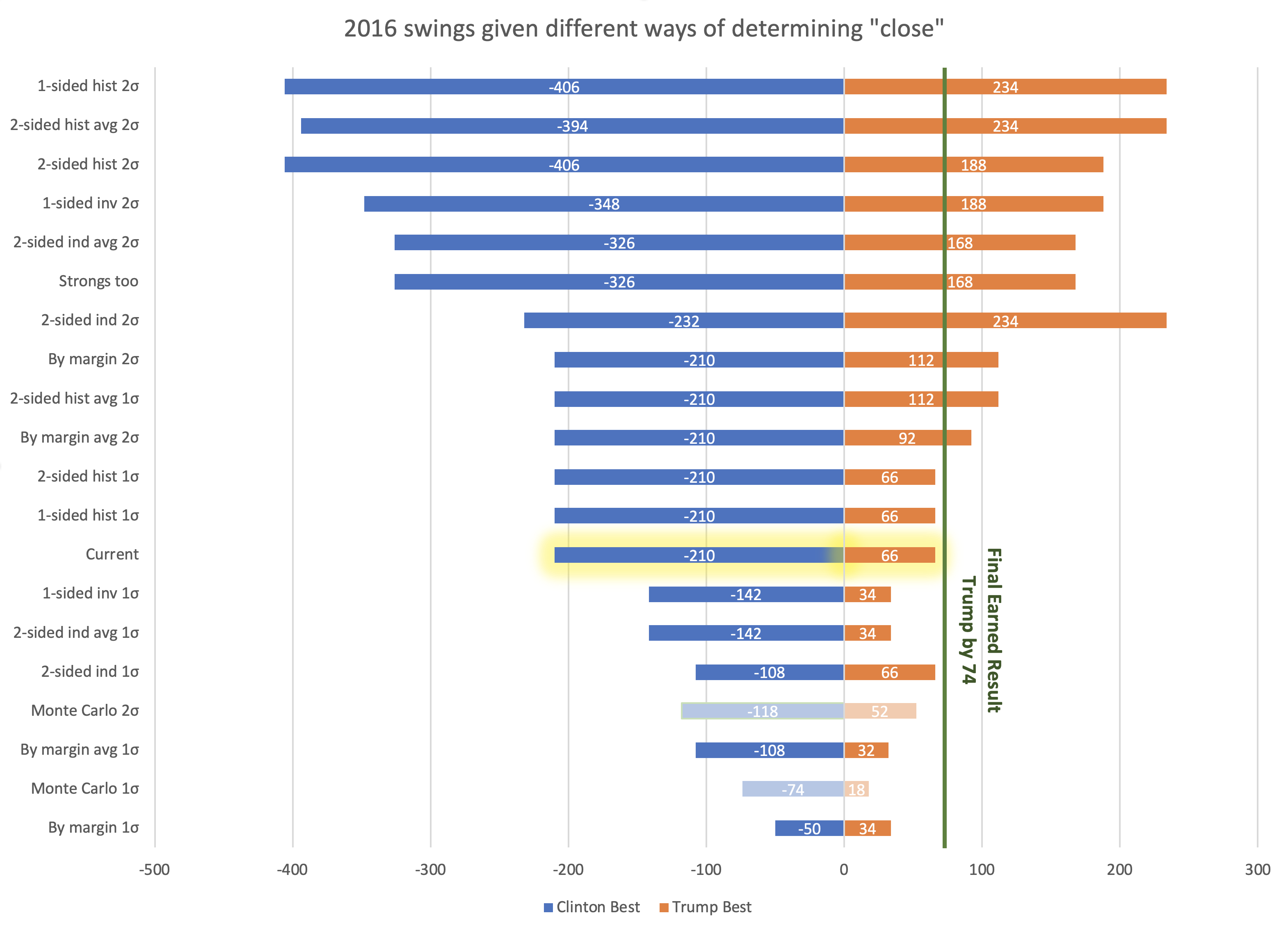
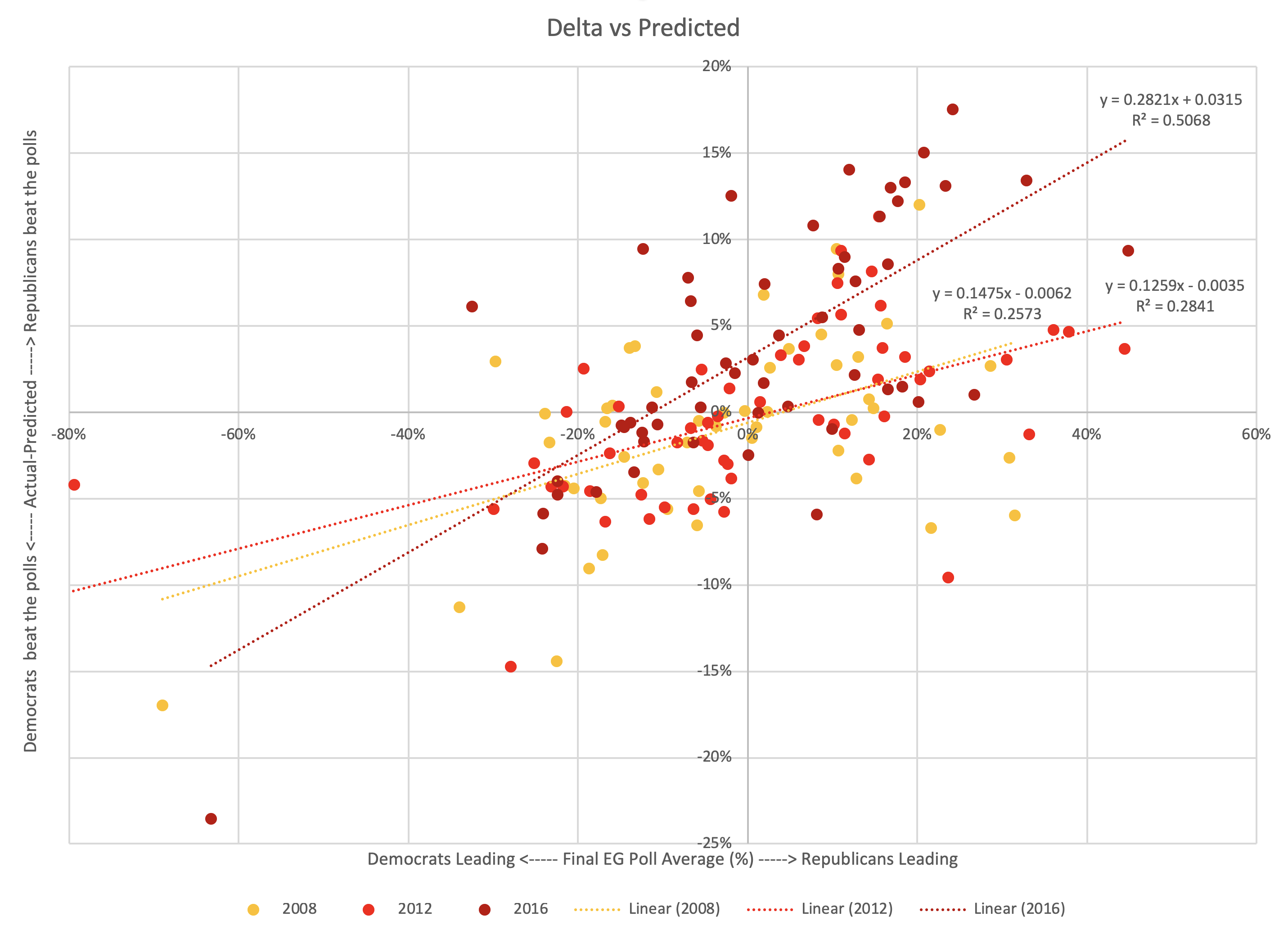
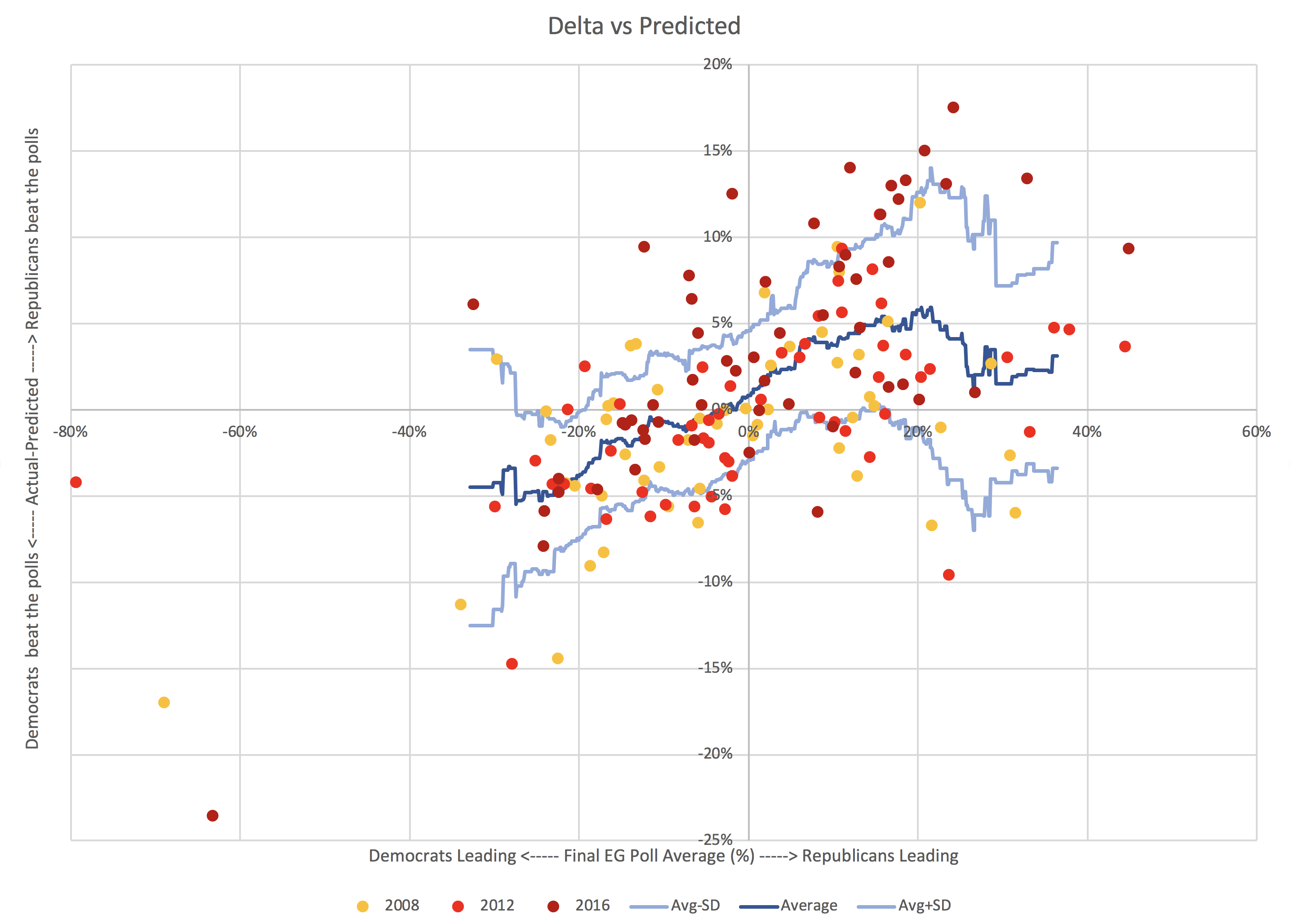
In the last few posts, I spent a lot of time on looking at various ways of determining what is a "close state". This is because in the past Election Graphs has defined three classifications:
- "Weak": Margin < 5% – States that really are too close to call. A significant polling error or rapid last minute movement before election day could flip the leader easily.
- "Strong": 5% < Margin < 10% – States where one candidate has a substantial lead, but where a big event could still move the state to "Weak" and put it into play.
- "Solid": Margin > 10% – States where one candidate's lead is substantial enough that nobody should take seriously the idea of the leader not actually winning.
The "main" chart on Election Graphs has been the Electoral College Trend Chart. The final version on Election Day 2016 looked like this:
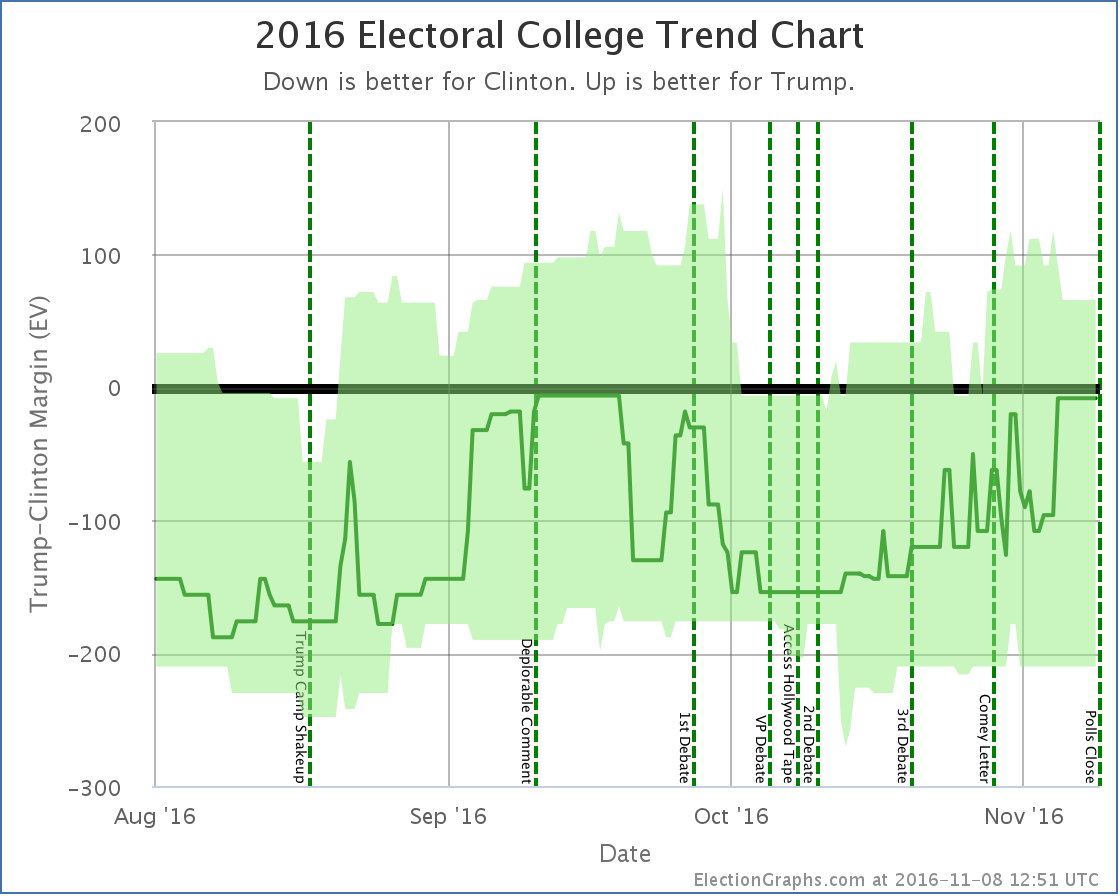
The "band" representing the range of possibilities goes from all the Weak states being won by the Democrat, to all the weak states being won by the Republican.
One of the reasons for all the analysis in this series is of course that this method yielded a "best case" for Trump of a 66 EV margin over Clinton. But the actual earned margin (not counting faithless electors) was 74 EV.
So the nagging question was if these bounds were too narrow. Would some sort of more rigorous analysis (as opposed to just choosing a round number like 5%) lead to a really obvious "oh yeah, you should use 6.7% as your boundary instead of 5%" realization or something like that.
After digging in and looking at this, the answer seems to be no.
As I said in several venues in the week prior to the 2016 election, a Trump win, while not the expected or most likely result given the polling, should not have been surprising. It was a close race. Trump had a clear path to victory.
But the fact he won by 74 EV (77 after faithless electors) actually was OK to be surprised about.
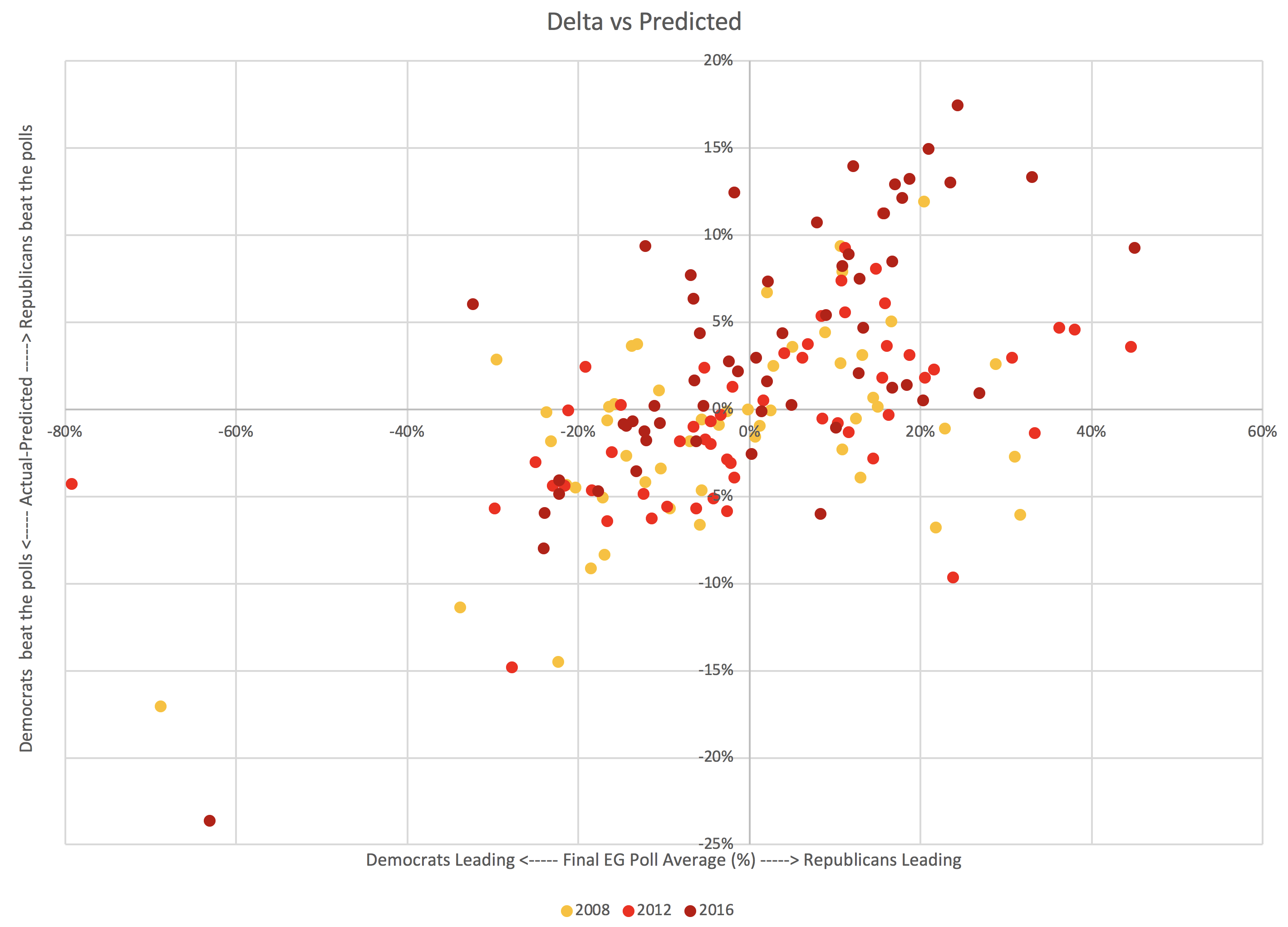
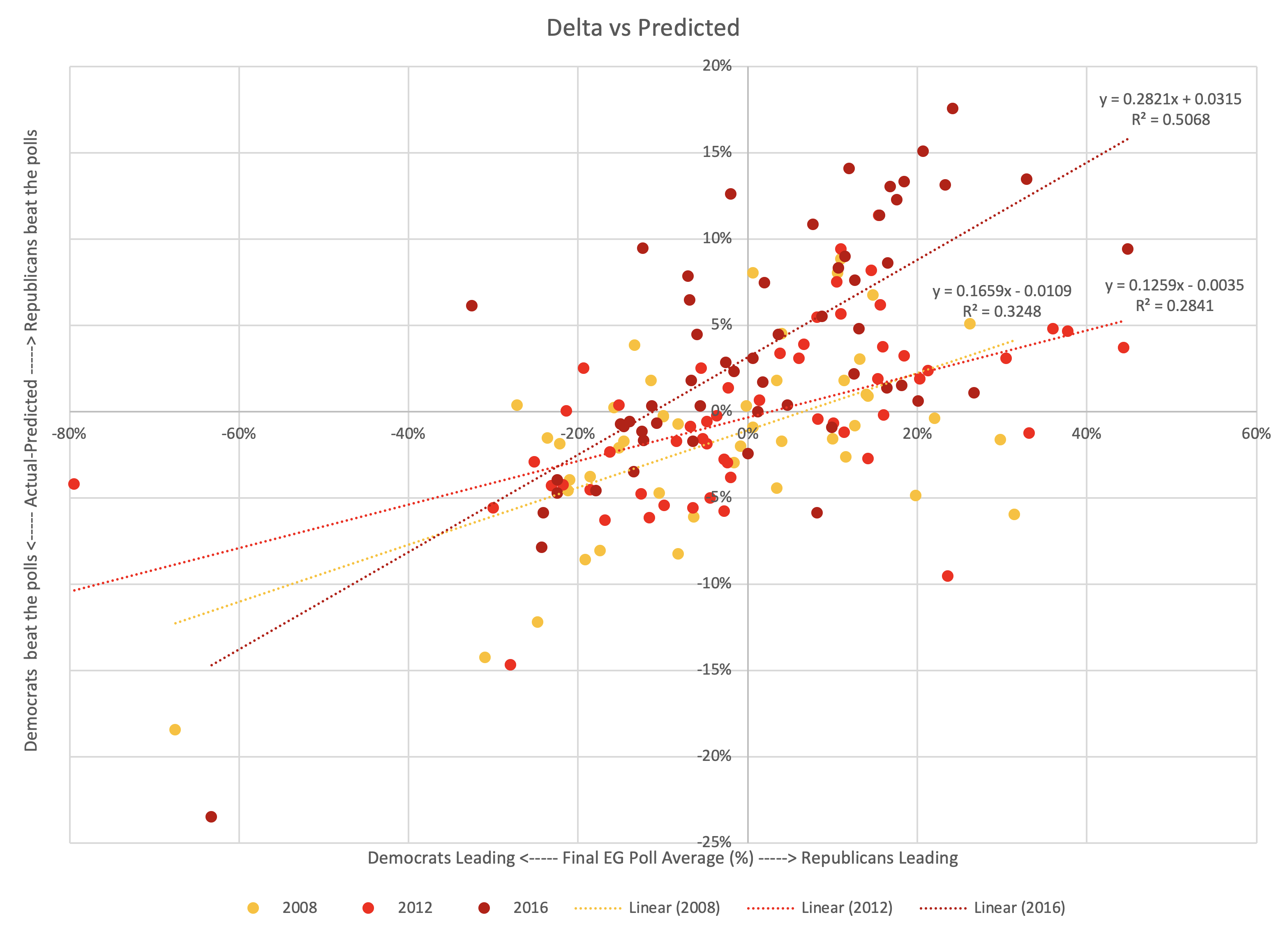
Specifically, the fact that he won in Wisconsin, where the Election Graphs poll average had Clinton up by 7.06% is an outlier based on looking at all the poll average vs actual results deltas from the last three cycles. It is the only state in 2016 where the result was actually surprising. Without Wisconsin, Trump would have won by 54 EV, which was within the "band".
Advantages of simplicity
So after all of that, and this will be very anti-climactic, I've decided to keep the 5% and 10% boundaries that I've used for 2008, 2012, and 2016.
Several of the ways of defining close states that I looked at in this series are actually quite tempting. I could just use the 1σ boundaries of one of the methods to replace my 5% boundary between "weak" and "strong" states, and the 2σ numbers to replace the 10% boundary between "strong" and "solid" states.
I could even use one of the asymmetrical methods that reflect that things may be different on the two sides.
But frankly, I keep coming back to the premise of Election Graphs being that something really simple can do just as well as fancy modeling.
From the 2016 post mortem here is a list of where a bunch of the election tracking sites ended up:
- Clinton 323 Trump 215 (108 EV Clinton margin) – Daily Kos
- Clinton 323 Trump 215 (108 EV Clinton margin) – Huffington Post
- Clinton 323 Trump 215 (108 EV Clinton margin) – Roth
- Clinton 323 Trump 215 (108 EV Clinton margin) – PollyVote
- Clinton 322 Trump 216 (106 EV Clinton margin) – New York Times
- Clinton 322 Trump 216 (106 EV Clinton margin) – Sabato
- Clinton 307 Trump 231 (76 EV Clinton margin) – Princeton Election Consortium
- Clinton 306 Trump 232 (74 EV Clinton margin) – Election Betting Odds
- Clinton 302 Trump 235 (67 EV Clinton margin) – FiveThirtyEight
- Clinton 276 Trump 262 (14 EV Clinton margin) – HorsesAss
- Clinton 273 Trump 265 (8 EV Clinton margin) – Election Graphs
- Clinton 272 Trump 266 (6 EV Clinton margin) – Real Clear Politics
- Clinton 232 Trump 306 (74 EV Trump margin) – Actual result
The only site (that I am aware of) that came closer to the actual result than I did was RCP… who like me just used a simple average, not a fancy model.
This says something about sticking with something simple.
Or maybe I was just lucky.
To be fair, there was a lot of movement just in the last day of poll updates. Before that, I had a 108 EV margin for Clinton as my expected case and would have been one of the worst sites instead of one of the best sites in terms of final predicted margin. Noticing that last minute Trump surge in the last few polls in some critical states was important, and the fact Election Graphs uses a "last 5 polls" methodology made our numbers able to pick up that change quickly.
But even aside from how close we got, a regular person who doesn't follow these things that closely could come to Election Graphs and just say "oh, close states are under 5%, they could go either way". More complex models have their places, but it hasn't been Election Graphs' niche. One of the main points of this site was always doing something relatively simple, and still getting decent results.
So. I'm sticking to 5% and 10%. Even though they are just nice round numbers, without a mathematical justification.
Because they are nice round numbers that are still reasonable for these purposes, and not too far out from numbers you COULD pick with some sort of mathematical hand waving if you wanted to.
So. Less than 5% for a weak state, less than 10% for a strong state, and over 10% is solid.
Just like before.
What about the tipping point?
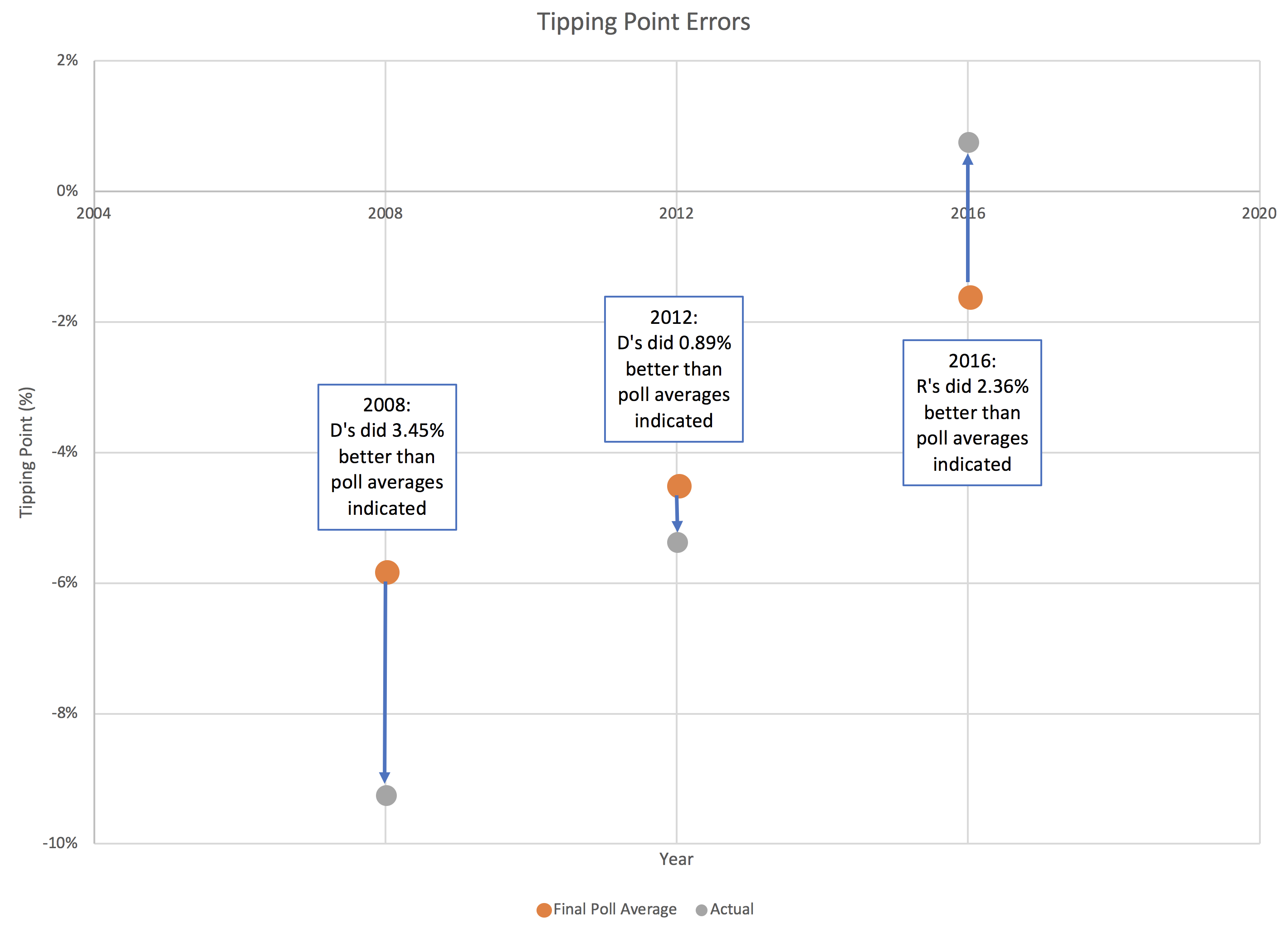
OK, with everything I have said about nice round boundaries, and keeping it simple, I think I will actually allow myself to move in the limits of what I show as "close" on the chart of the tipping point. Maybe 5% is too close to call on a state level, but if the tipping point is at 5%, that is more substantial.
Having said that, 2016 did see 6% swings in the tipping point within two week periods of time. It can move quite a bit, quite quickly. So of course, just watch, 2020 will see someone with a 6% lead in the tipping point on election day proceed to lose the race. But for now, I feel OK tightening these bounds.
I'll be using the 2.36% and 3.45% levels described in the last post to really emphasize that if you are in that zone, you have a super close race. Regardless of what the electoral college center line is, or the "best case" scenarios for the two candidates, if we see a 1% tipping point margin again, it would be crazy not to emphasize that you are looking at a race that is too close to call.
[Note added 2019-03-01: Once I started actually building out the 2020 site, I tried changing the limits for the tipping point as described above, but with everything else left at 5% and 10%, it looked out of place, so I actually left them at 5% and 10% as well. So alas, all this analysis of other ways to define limits that were not nice round numbers ended up with me just using the nice round numbers from before.]
What about that Monte Carlo thing?
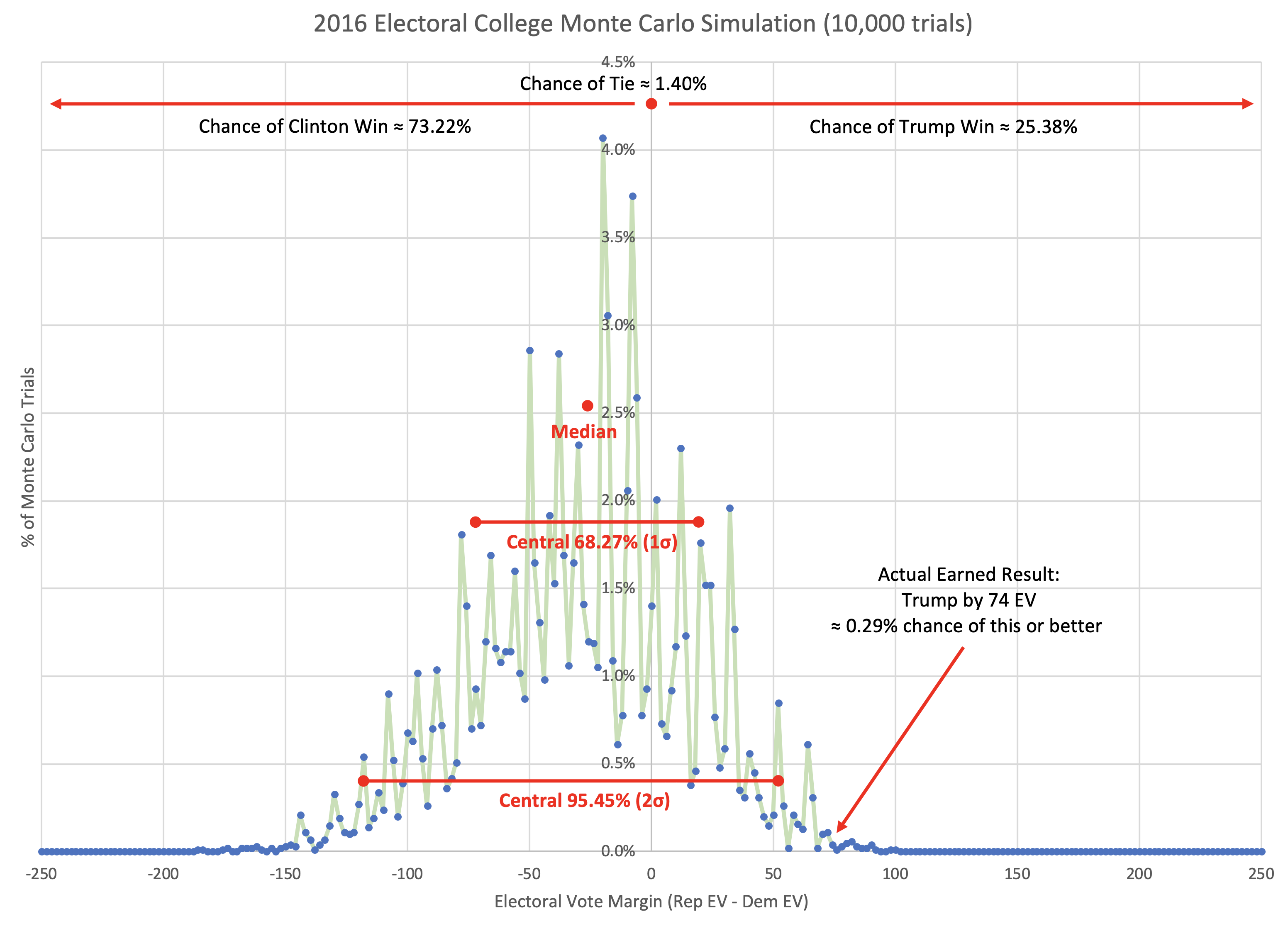
Well, once again ignoring everything I said above about simplicity, I've never quite liked the fact that the "band" is generated by swinging ALL the close states back and forth, which is actually not very likely. The fact that a bunch of states are close and could go either way, does not imply that it would be easily possible for them to ALL flip the same direction at the same time. (Although yes, if polling assumptions are all wrong the same way, all the polling may be off in the same direction.)
Election Graphs shows that whole range of possibility, with no way of showing some outcomes within the range are more likely than others, or that some outcomes outside the range actually are still possible, just less likely. It would be nice to add some nuance to that.
And I'll be honest, I've been slowly introducing more complexity over the last three cycles, and I kind of enjoy it. For instance, the logic for how to determine which polls to include in the "5 poll average" that I used in 2016 has a lot more going on than what I did in 2008 or 2012. And for that matter, in 2016 everything was generated automatically from the raw poll data, while in previous cycles I did everything by hand. Progress!
So… while I am going to keep the main display using the 5% and 10% boundaries, I am actually kind of excited to now have a structured way to also do a Monte Carlo style model…
I would use the data from the Polling Error vs Final Margin post to do some simulations and show win odds and electoral college probability distributions as they change over time as well as the current numbers. I have a vision in my head for how I would want it all to look.
But that would be an alternative view, not the main one… if I actually have time.
The plan
I had originally intended to have the 2020 site up by the day after the 2018 midterms. Then I'd hoped to be done by the end of November. Then December. Then January. But life and other priorities kept getting in the way.
I'd also intended to launch with a variety of changes and refinements over the 2016 site, including perhaps changing the 5% and 10% bounds, but also other things. Some changes to how some of the charts look. Additional changes to how the average itself was calculated. A completely different alternative view to switch to if a third party was actually strong enough to win electoral votes. Or the Monte Carlo view. Or making the site mobile friendly. Or a bunch of other things.
But frankly, I've just run out of time. I now know of seven state level general election matchup polls for 2020 that are already out, and there are probably more I have missed. And the pace is increasing rapidly now that candidates are announcing. So there are already results I could be showing.
(Yes, I am quite aware that general election match up polls this far out are not predictive of the actual election at all, but they still tell you something about where things are NOW.)
So at this point my priority is to just get the site up and running as fast as possible, which means making all the logic and visuals an exact clone of 2016, just with 2020 data. At least to start with.
After that, I'll start layering in changes or additions if and when I have time to do so. I still hope to be able to do a variety of things, but that depends on many factors, so I'm not making any promises at this point. I'll do what I can.
So that's the plan.
Conclusion
I have been dragging my feet working off and on (mostly off) on collecting the data, making the graphs, and writing my little commentary on this series of posts for literally more than six months. Maybe more than nine months. I forget exactly when I started.
If there are any of you who have actually read all of this to the end, thank you. I don't expect there are many of you, if any. That's just the way it goes.
But I felt like I needed to get all this done and out before starting to set up the 2020 site. I wanted to see what the results of looking at this old data would show, and I wanted to share it. Maybe I didn't really need to and it was just an excuse to procrastinate on doing the actual site.
But I have no more excuses left. Time to start getting the 2020 site ready to go… I'll hopefully have the basics up very soon.
Stay tuned!
You can find all the posts in this series here:
{kind=link}
{kind=link}